本文仅记录学习volatile与final关键字过程中觉得需要仔细理解的地方,用于备忘,具体关于volatile与final使用方法及介绍,可参考:深入理解Java内存模型(四)——volatile 等文章。
volatile相关
JSR-133为什么要增强volatile的内存语义
在JSR-133规范发布之前,volatile变量的访问和非volatile变量的访问之间可以自由的重排序,如下例:
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
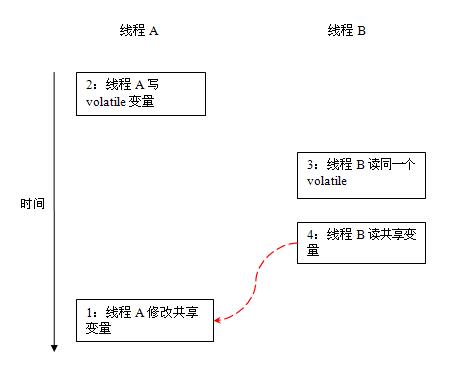
假设有两个线程A和B,A首先执行Writer方法,随后B线程接着执行Reader方法,在老的内存模型中,1和2重排序后,其执行顺序可能如下:
3和4重排序后,其执行顺序可能如下:
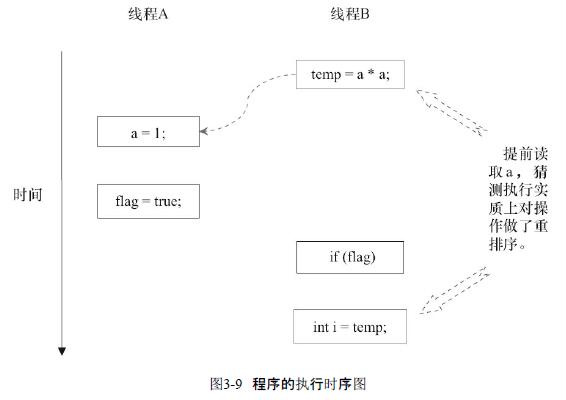
在旧的内存模型中,当1和2之间没有数据依赖关系时,1和2之间就可能被重排序(3和4类似)。其结果就是:读线程B执行4时,不一定能看到写线程A在执行1时对共享变量的修改,导致4中读到的值为0。
在JSR-133中,加强了volatile变量的语义,需要有acquire和release语义。通过此方式在volatile变量的写-读之间建立了happens-before关系。
volatile关键字通过加入内存屏障之后具有的两个作用:
- 不允许随意重排序(store-store、load-load、load-store内存屏障)
- volatile变量写对于之后的读可见(store-load内存屏障)
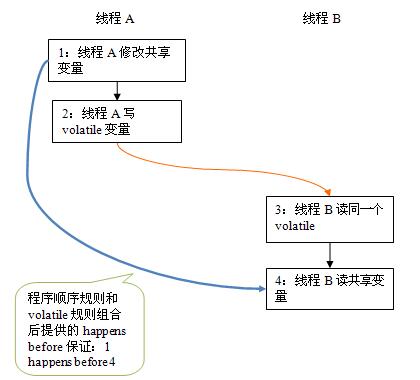
通过happens-before关系建立原则,由于flag为volatile变量,所以有2 happens-before 3,由程序顺序原则有 1 happens-before 2, 3 happens-before 4,所以由传递性规则得到1 happens-before 4,所以在writer()方法执行之后,reader()方法中一定可以读取到a变量的值为1,其具体执行顺序图如下:
使用volatile解决单例模式中的双重检测锁问题
在介绍DCL方式实现单例模式的问题之前,先介绍下创建一个对象的过程:
instance = new Singleton();
这一行代码可以分解为如下的三行伪代码:
memory = allocate(); // 1:分配对象的内存空间
ctorInstance(memory); // 2:初始化对象
instance = memory; // 3:设置instance指向刚分配的内存地址
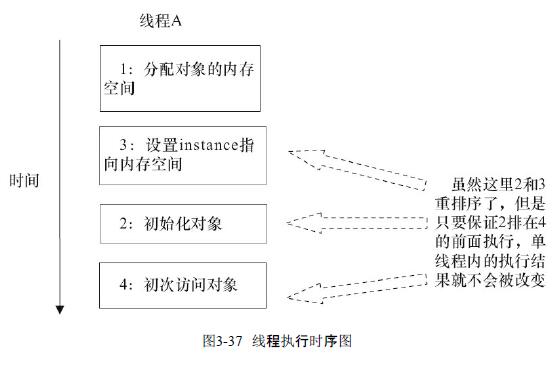
在上面三行伪代码中的2和3之间,可能会被重排序。2和3之间重排序之后的执行时序如下。
memory = allocate(); // 1:分配对象的内存空间
instance = memory; // 2:设置instance指向刚分配的内存地址,注意,此时对象还没有被初始化!!!
ctorInstance(memory); // 3:初始化对象
虽然这里2和3重排序了,但是在单线程执行的过程中在创建对象操作与初次访问对象之间是存在happens-before关系的,所以可以保证在初次访问对象时对象创建肯定已经完成。示例图如下:
但是如果一个对象在创建过程中可以被对个线程同时可见,就有可能发生一个线程访问到初始化尚未完成的对象的情况,示例图如下:
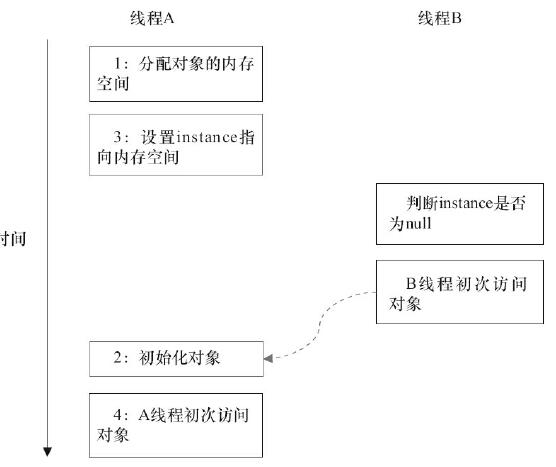
双重检测锁方式实现单例模式的问题就在于此,这种单例模式返回的对象有可能是构造函数未执行的不稳定的对象:
class Item {
public int count;
public Item(int count) {
this.count = count;
}
}
class DCLSingleInstance {
private static DCLSingleInstance dclSingleInstance;
private Item[] items;
public Item item;
private int k;
private DCLSingleInstance() {
items = new Item[]{new Item(50), new Item(60)};
item = new Item(40); // item对象可能构造函数未执行完毕就返回了
k = 20;
}
public static DCLSingleInstance getDclSingleInstance() {
if (dclSingleInstance == null) { // 2
synchronized (DCLSingleInstance.class) {
if (dclSingleInstance == null) {
dclSingleInstance = new DCLSingleInstance(); // 1
}
}
}
return dclSingleInstance;
}
public void setK(int k) {
this.k = k;
}
}
其造成问题的多线程执行时序图如下:
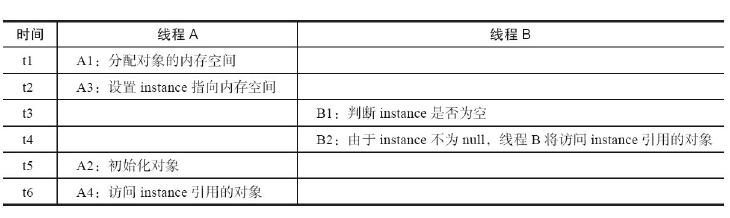
解决这个问题的方法之一是将dclSingleInstance 声明为volatile的,这样就在操作1和操作2之间建立了happens-before关系,使得线程A在操作1及其之前的执行结果对于线程B来说是可见的,这样就不会出现线程B访问到一个还未初始化的对象的问题。
(个人猜测待验证)需要注意的是,线程B如果执行dclSingleInstance.item.count获取的值一定是40,不可能是0,这是由1与2之间的happens-before关系决定的,ThreadA在1操作及其之前的所有操作对于ThreadB来说是一定可见的。
即使使用volatile修复了DCL中的问题,由于这种单例模式的实现每次获取对象时都需要读取一个volatile变量,这就产生了额外的同步操作开销,即使volatile的开销很低。相比于DCL单例模式,一种更好的实现单例模式的方法是静态内部类方式:
class SingleInstance {
private static class SingleInstanceHolder {
private static SingleInstance SINGLE_INSTANCE = new SingleInstance();
}
private SingleInstance() {}
public static SingleInstance getInstance() {
return SingleInstanceHolder.SINGLE_INSTANCE;
}
}
volatile引用中成员变量并不volatile
两个线程同时持有一个DCLSingleInstance类的对象dclSingleInstance:
- 其中一个线程通过dclSingleInstance = new DCLSingleInstance() 将dclSingleInstance指向新的位置,如果dclSingleInstance声明时是volatile的,另一个线程能够立即感知到指向的变化;
- 其中一个线程通过dclSingleInstance.setK(int k)方法更改k的值,另一个线程能否看到,何时看到都是不确定的。
使用volatile解决long、double变量写操作的原子性问题
在一些32位的处理器上,如果要求对64位数据的写操作具有原子性,会有比较大的开销。为了照顾这种处理器,Java语言规范鼓励但不强求JVM对64位的long型变量和double型变量的写操作具有原子性。当JVM在这种处理器上运行时,可能会把一个64位long/double型变量的写操作拆分为两个32位的写操作来执行。这两个32位的写操作可能会被分配到不同的总线事务中执行,此时对这个64位变量的写操作将不具有原子性。
volatile在实现时规定将volatile加在long、double变量的声明中可以保证对其写操作的原子性。
还要注意一点是对volatile变量读写是原子性的,但volatile++不是原子性的。
更多关于volatile使用相关知识,可参考:Java 理论与实践-正确使用 Volatile 变量
final相关
以下引用自[翻译]JSR 133 (Java Memory Model) FAQ:
final字段的值看起来会变的最好例子之一涉及到String类的一个特殊实现。
String可以实现成包含三个字段——一个字符数组,位于数组中的偏移量,和长度。以这种方式实现String而不是只要一个字符数组是因为这样可以让多个String和StringBuffer对象共享同一个字符数组,避免了额外的对象分配与拷贝。所以,如方法String.substring()可以实现成创建一个共用原String字符数组的String对象,仅是长度和偏移量字段的值不一样。String中这些字段都是final的。 String s1 = “/usr/tmp”; String s2 = s1.substring(4);
s2字符串的偏移量将是4,长度为4.但是,在老的模型下,其它线程有可能先看到它的偏移量是默认值0,随后再看到正确的值4,看起来像是”/usr”变成了”/tmp”。
最初的Java内存模型允许这种行为;有几个JVM已经表现出了这种行为。新的Java内存模型则不允许这样。
在JDK5之前确实可能出现上述的情况,这是由于虽然String类中偏移量字段声明是final的,但是由于老的内存模型的缺陷,可能对象引用已经返回,而final字段的赋值操作还没有做,这就会导致上述情况。
在JSR-133中,加强了final关键字的语义,假设对象时正确构造的,一旦一个对象被构建,构造器中赋给final字段的值无需同步就将对其它线程可见。此外,这些final字段引用的对象或数组的可见值起码是final字段中最新的。
更多关于final关键字使用相关内容可参考:深入理解Java内存模型(六)——final,这里不再重复论述,这篇文章中提到的内容中我觉得需要仔细理解的一个地方就是如果final字段是一个引用,final字段所引用的对象里的字段和数组元素可能在后续还会变化(final引用中成员变量并不默认final),若没有正确同步,其它线程也许不能看到最新改变的值,但一定可以看到完全初始化的对象或数组被final字段引用的那个时刻的对象字段值或数组元素。
class Item {
private int count;
public Item(int count) {
this.count = count;
}
}
class FinalReferenceExample {
final Item item;
final int[] intArray; //final是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample () { //构造函数
intArray = new int[1]; //1
intArray[0] = 1; //2
item = new Item(30);
}
public static void writerOne () { //写线程A执行
obj = new FinalReferenceExample (); //3
}
public static void reader () { //读线程C执行
if (obj != null) { //5
int temp1 = obj.intArray[0]; //6
}
}
}
在writerOne方法被调用之后,obj.item.count值一定为30。
(完)